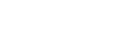

解决方案
世芯信息基于软硬件全栈自研能力,为不同行业客户提供场景化、定制化、一体化的算力与数据基础设施解决方案,帮助客户实现业务快速部署、平稳运行与智能化升级。
AI算力整合解决方案
随着人工智能技术的普及和大模型的快速演进,企业在AI基础设施建设中普遍面临GPU资源紧缺,硬件选型复杂、交付周期长;算力部署与管理技术门槛高,难以快速上手;模型训练/推理过程中资源浪费严重,能耗居高不下;算力系统与现有业务平台难以整合,缺乏弹性与可控性。企业不仅需要高性能的AI训练推理平台,更希望具备快速部署、弹性调度、统一运维、资源可视的综合平台,提升算力使用效率,降低成本,并能够平滑地对接自己的业务开发体系。

硬件架构方面以“IB网络+GPU集群+并行存储”架构和高性能服务器为算力支持,能够充分满足深度学习进程中训练和推理双重需求。结合并行存储系统,,满足高带宽和高并发的海量文件寻取,为客户业务带来高效的存储性能体验。
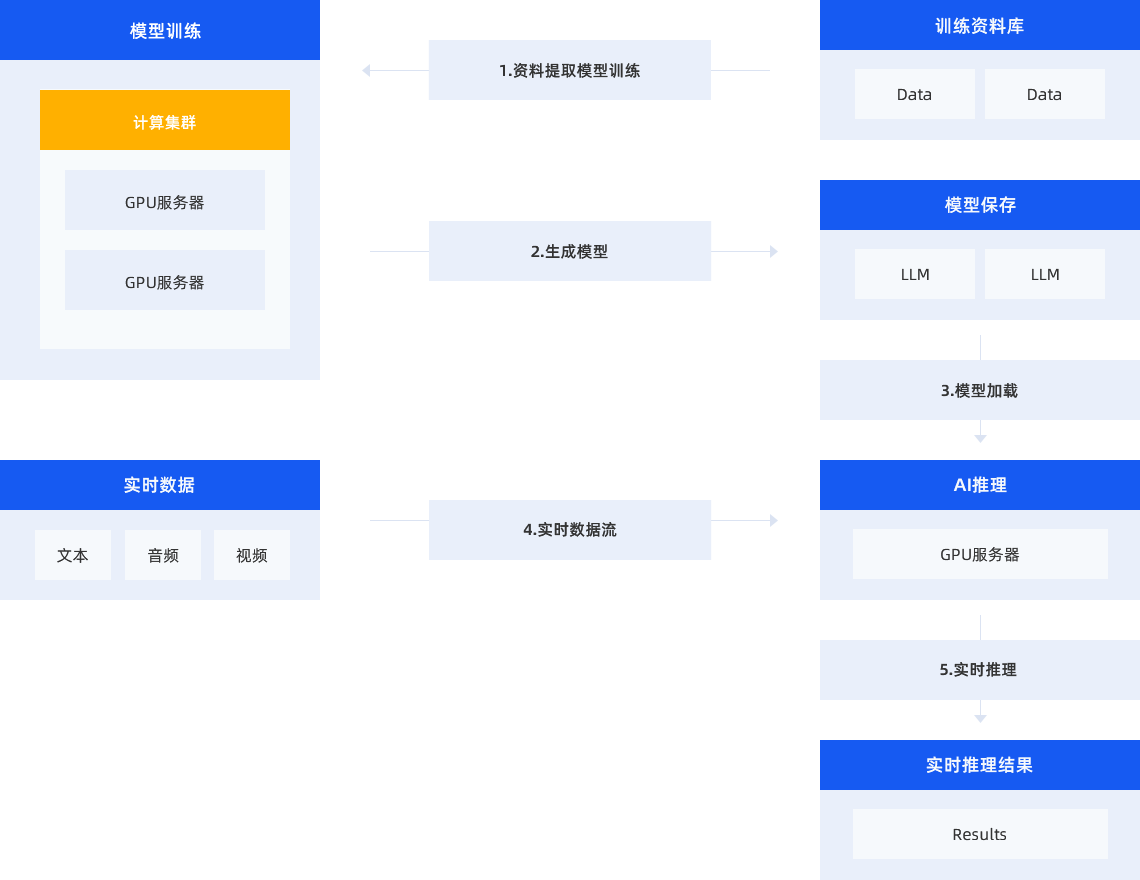
世芯信息AI管理平台从业务需求出发,支持主流学习框架(如TensorFlow, Caffe, Torch, Keras)提供了开发和训练机器学习模型的基础环境,它们可以通过标准化接口访问深度学习算法库中的各种模型;深度学习算法库(如LeNet, AlexNet, GAN等),用于解决具体的机器学习任务,客户可以在这些框架上调用这些算法库进行模型训练;标准数据集(如ImageNet, COCO等)提供了训练和测试模型所需的样本数据,机器学习框架和算法库会从这些数据集中获取数据进行模型训练和验证。
方案特点
-
 AI服务器底座采用多GPU异构架构,支持NVIDIA A100/H100、AMD MI300等主流计算芯片,专为大模型训练、推理部署等AI密集任务设计
AI服务器底座采用多GPU异构架构,支持NVIDIA A100/H100、AMD MI300等主流计算芯片,专为大模型训练、推理部署等AI密集任务设计 -
 算力资源管理平台提供算力池化、任务调度、GPU虚拟化、能耗控制等功能,帮助客户实现多租户使用与弹性管理
算力资源管理平台提供算力池化、任务调度、GPU虚拟化、能耗控制等功能,帮助客户实现多租户使用与弹性管理 -
 业务集成与开发接口对接主流AI框架(PyTorch、TensorFlow)、提供SDK/API供客户对接现有模型训练/推理流程
业务集成与开发接口对接主流AI框架(PyTorch、TensorFlow)、提供SDK/API供客户对接现有模型训练/推理流程 -
 数据与模型协同支持结合世芯信息UniStorage数据系统与AI服务器,为客户提供数据-模型-算力协同部署的一体化方案
数据与模型协同支持结合世芯信息UniStorage数据系统与AI服务器,为客户提供数据-模型-算力协同部署的一体化方案